The European Commission's Joint Research Center is working on a tool that could use tweets and artificial intelligence to collect real-time data on floods. In a paper released on Arvix.org, EU scientists explain how their Social Media for Flood Risk (SMFR) prototype could help emergency responders better understand what's happening on the ground in flooded areas and determine what trouble spots might need immediate attention.
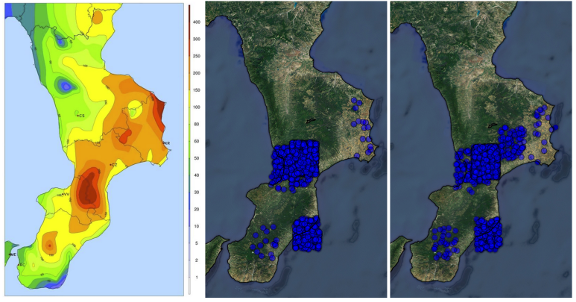
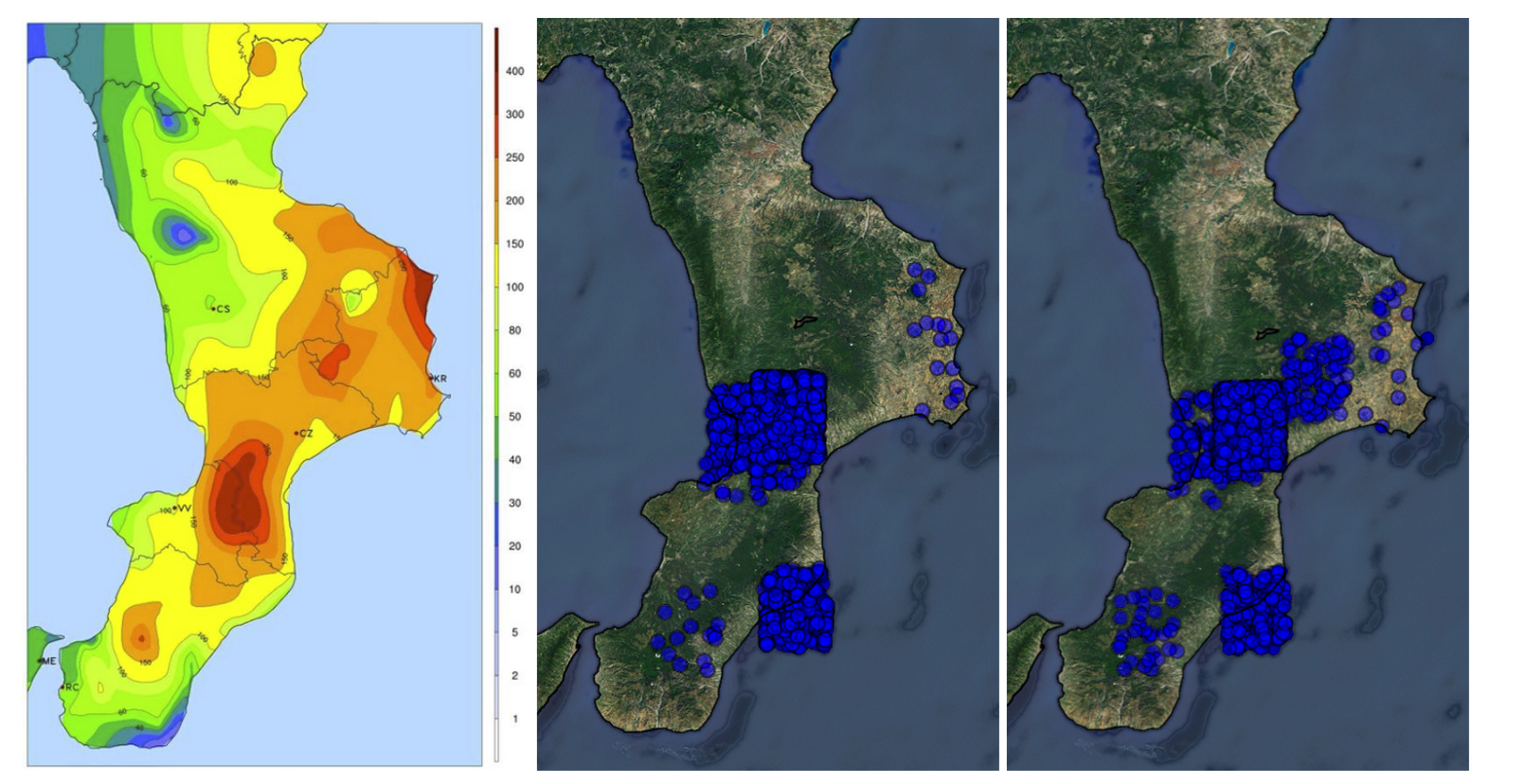
The tool works in collaboration with Europe's Flood Awareness System (EFAS). When EFAS identifies areas with heightened flood risks, it triggers SMFR to begin collecting flood-related tweets from users in those areas. Gathering reliable information from Twitter is no easy task, especially considering that EFAS covers an area with more than 27 languages. That's where the team put AI to work. To start, the researchers trained SMFR to spot flood-related keywords in English, German, Spanish and French. In a test during floods in Calabria, Italy, last fall, the tool successfully gathered 14,347 tweets over three days, sorted them by relevance and provided geo-location data.
Continue reading in Engadget »
Valerio Lorini, Carlos Castillo, Francesco Dottori, Milan Kalas, Domenico Nappo, Pater Salamon: Integrating Social Media into a Pan-European Flood Awareness System: A Multilingual Approach. To appear in ISCRAM. Valencia, Spain. [arxiv]