QCRI/AJE press release: QCRI and Al Jazeera launch predictive web analytics platform for news
New platform developed by QCRI and Al Jazeera can predict visits to news articles by taking cues from social media
News organisations have vast archives of information, as well as a number of web analytic tools that aid in allocating editorial resources to cover different news events, and capitalise on this information. These tools allow editors and media managers to react to shifts in their audience’s interest, but what is lacking is a tool to help predict such shifts.
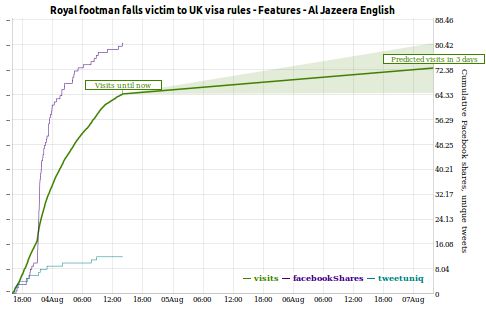
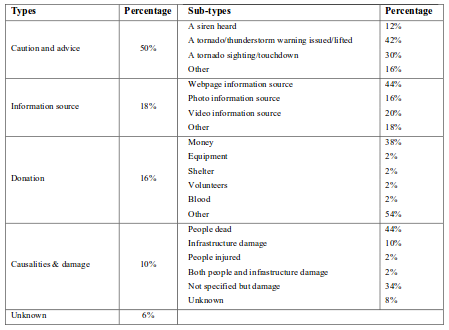
Qatar Computing Research Institute (QCRI) and Al Jazeera are announcing the launch of FAST (Forecast and Analytics of Social Media and Traffic), a platform that analyses in real-time the life cycle of news stories on the web and social media, and provides predictive analytics that gauge audience interest.
“The explosion of big data in the media domain has provided QCRI an excellent research opportunity to develop an innovative way to derive value from the information,” said Dr Ahmed Elmagarmid, Executive Director of QCRI. “Together with our valued partner, Al Jazeera, the QCRI team has developed a platform that will help shift the way media does business.”
“Al Jazeera English’s website thrives on good original content in news and features, dynamic ways of creativity through interactive and crowd sourcing methods, and up-to-date social media tools. We welcome working with QCRI in developing FAST as it allows us to understand the consumption of news and what is expected to do well in driving traffic forward. Analytics in predicting the future trend of a web story is a crucial component in understanding web traffic, this initiative is a component we welcome,” said Imad Musa, Head of Online for Al Jazeera English.
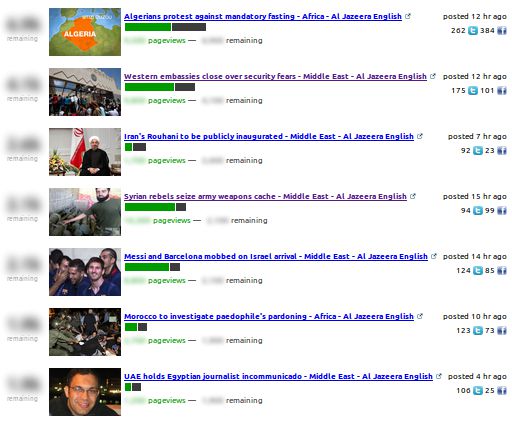
You can test the platform at http://fast.qcri.org/ and read the full press release at the QCRI website. The system is based on research described in the following paper:
 Wired UK, 30 September 2013.
Wired UK, 30 September 2013.